Szybki rozwój modeli AI – porównanie liderów i narodziny nowego przełomowego modelu Gemini 3.1 Pro
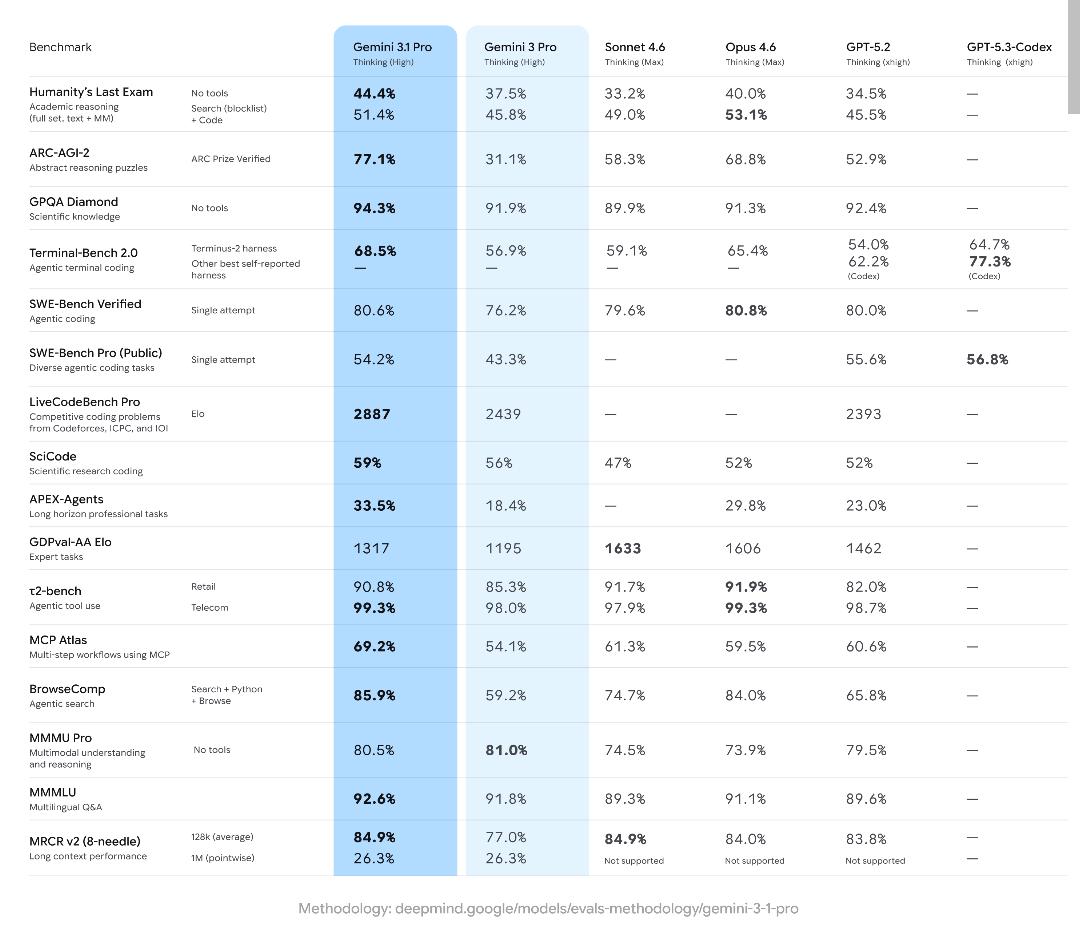
Najnowsze tygodnie przynoszą lawinę doniesień o Gemini 3.1 Pro – nowym flagowym modelu AI od Google. Model ten zadebiutował 19 lutego 2026 i natychmiast zdeklasował konkurencję (Claude Sonnet 4.6, GPT-5.2) w wielu testach: m.in. osiągnął 77,1% na benchmarku ARC-AGI-2 (ponad dwukrotnie lepiej niż poprzednik), 94,3% na GPQA Diamond oraz 80,6% na SWE-Bench Verified. Gemini 3.1 Pro wyróżnia się wyjątkowymi zdolnościami do automatycznego kodowania, rozumowania, pracy z multimodalnymi danymi (tekst, obraz, wideo, dźwięk), generować animowane SVG oraz obsługować okna kontekstowe do 1 mln tokenów. Można go testować przez aplikację Gemini, NotebookLM, Google AI Studio czy Vertex AI, a dla płatnych użytkowników dostępne są wyższe limity. Model został też doceniony za skuteczne eliminowanie „halucynacji” (generowania nieprawdziwych odpowiedzi), choć w trudnych, nowatorskich zadaniach nadal zdarzają się błędy.
Obraz to metaforyczne zestawienie rozwoju AI – od „najpotężniejszego modelu na świecie” (symbolizowanego logo AI), przez historyczny wkład OpenAI, po podkreślenie aktualnej pozycji Gemini jako lidera. Schematyczne strzałki wskazują dynamiczny postęp technologiczny w tej dziedzinie.
Wokół premiery powstało wiele porównań – na obrazkach i animacjach zestawia się Gemini z konkurentami, podkreślając różnice w jakości generowanych grafik (np. modele samochodów Ferrari w stylu Gemini 3.1 Pro i Claude Opus 4.6 czy benchmarki kodowania, gdzie Gemini wyprzedza GPT-5.2 i Claude’a).
Entuzjaści i testerzy uważają model za przełomowy w praktycznych zadaniach – zarówno w generowaniu kodu (czysty React, Python, Golang), jak i projektowaniu UI czy generowaniu rysunków SVG. Wprowadzone innowacje to także lepsze zarządzanie parametrami podczas uczenia, co pozwala podnieść wydajność nawet o 19% bez zwiększenia obciążenia obliczeniowego. Pojawiają się też głosy o efektywniejszym radzeniu sobie z tzw. „car wash test” (model domyśla się, że auto trzeba zawieźć do myjni, a nie iść na piechotę).
Ogółem – najnowsza fala modeli AI, z Gemini 3.1 Pro na czele, ustanawia poprzeczkę dla całej branży, a Google mocno podkreśla postęp w jakości, wydajności i praktyczności tego rozwiązania.
theneuron.ai · blog.google · deepmind.google · sea.mashable.com · artificialanalysis.ai · medium.com · arxiv.org
Animowane porównanie Gemini 3 a 3.1 Pro – rewolucja w generowaniu grafik SVG z tekstu
Na wideo przedstawiono dynamiczne porównanie animowanych grafik SVG, które powstały z tekstowych poleceń typu „pelikan jadący na rowerze”. Najnowszy model Google – Gemini 3.1 Pro – znacznie przewyższa starego Gemini 3 Pro pod względem realizmu, kompletności i detali (np. widać prawidłowo odwzorowane ciało pelikana, ramę roweru, łańcuch, pedały). Poprzednie wersje modeli AI bardzo często generowały uproszczone, nierealistyczne lub niepełne rysunki. Teraz obrazy są nie tylko spójniejsze, ale także zgodne z logiką fizyczną. Technologia bazuje na czystym kodzie SVG, co pozwala uzyskać bardzo małe pliki i łatwą skalowalność. To ważny krok w rozwoju AI do zadań wymagających generowania precyzyjnej, animowanej grafiki wektorowej na podstawie krótkich opisów tekstowych.
v.redd.it
Porównanie stylów generowania obrazów Ferrari przez różne modele AI
Obrazek ukazuje różnice w tym, jak modele Gemini 3.1 Pro i Claude Opus 4.6 realizują to samo polecenie („narysuj czerwonego Ferrari jako SVG w HTML”). Po lewej stronie dzieło Gemini 3.1 Pro charakteryzuje się nowoczesnym, aerodynamicznym wyglądem i dbałością o detale, po prawej Claude Opus 4.6 tworzy uproszczony, bardziej kreskówkowy samochodzik z przerysowanymi kołami. Zestawienie podkreśla rozbieżności w stylu i zaawansowaniu generowanej grafiki przez różne modele konkurenyjne, przy tym Ferrari Gemini jest wizualnie bardziej zbliżone do prawdziwego supersamochodu.
Kasparow o roli maszyn i ludzi w przyszłości AI – czy komputery mogą przebić człowieka?

Obraz przedstawia fragment wywiadu z Garrym Kasparowem, legendarnym szachistą, który słynie ze swoich poglądów na rozwój sztucznej inteligencji po słynnym meczu z Deep Blue. Kasparow wskazuje, że choć komputery są nieocenionym narzędziem, to jego zdaniem nie są w stanie dorównać ludzkiej intuicji i kreatywności. Na pytania o możliwą dominację maszyn w szachach i innych dziedzinach odpowiada sceptycznie, twierdząc m.in., że AI nie potrafi napisać literatury czy poprowadzić wywiadu tak jak człowiek. Ten głos pokazuje napięcie w debacie o tym, czy AI to tylko narzędzie, czy może faktycznie kiedyś przewyższy możliwości człowieka.
LLMy w silikonie – Taalas prezentuje chip z modelem AI o błyskawicznym działaniu i niskich kosztach
Firma Taalas ogłosiła rewolucyjny sposób budowania modeli językowych AI: zamiast klasycznego oprogramowania – architektura modelu i jego wagi są „wypiekane” bezpośrednio w krzemowym chipie. Dzięki temu model Lllama 3.1 8B generuje do 16 000 tokenów na sekundę przy latencji poniżej 1 ms i nawet 20-krotnie niższych kosztach produkcji oraz 10-krotnie mniejszym zużyciu energii względem tradycyjnych rozwiązań. Jest to możliwe dzięki szybkiemu cyklowi realizacji („od kodu do krzemu” w 60 dni), co może szczególnie przydać się np. dla modeli stosowanych w czasie rzeczywistym do rozpoznawania mowy czy generowania awatarów. Układ nie wymaga drogiego sprzętu (HBM, chłodzenia, itp.), a mimo „wypieczenia” obsługuje LoRA (dostosowywanie pod konkretne zastosowania).
reddit.com · taalas.com
Gemini 3.1 Pro liderem w Artificial Analysis Coding Index – nowy standard w AI do kodowania
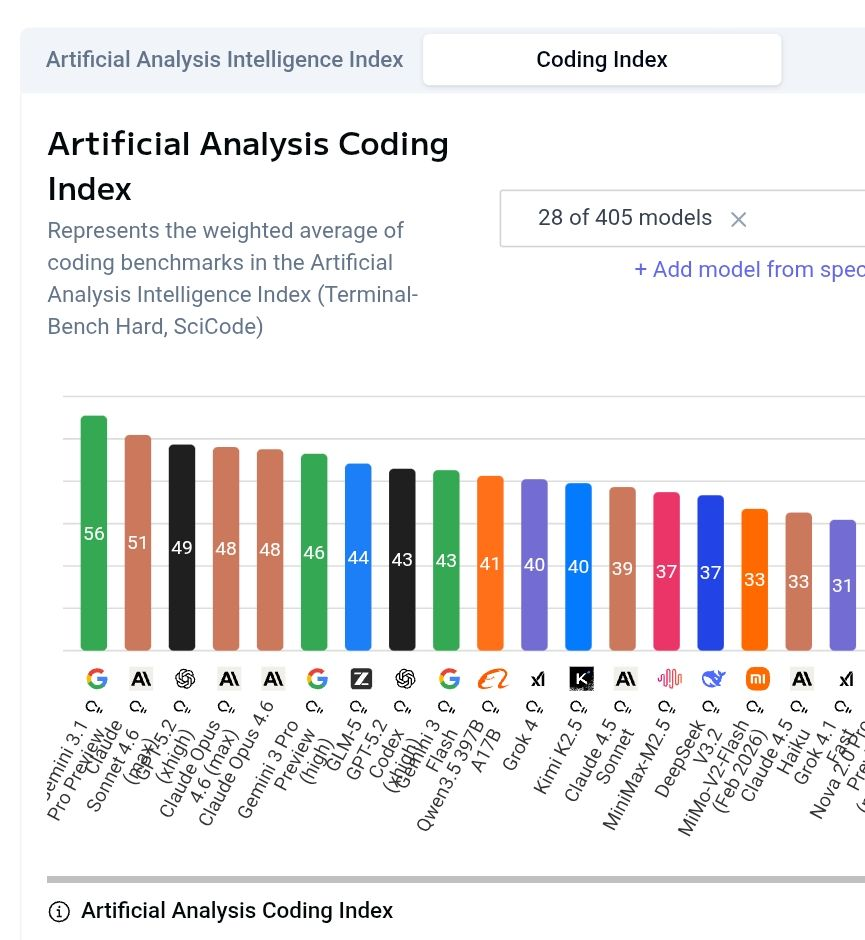
Model Gemini 3.1 Pro Preview zdeklasował konkurencję w rankingach Artificial Analysis Coding Index, osiągając najwyższe wyniki w benchmarkach programistycznych takich jak Terminal-Bench Hard (54%) czy SciCode (59%). Na szerszym indeksie IQ zajmuje też pierwsze miejsce, wyprzedzając modele Claude Opus 4.6 i GPT-5.2. Dodatkowym atutem jest niższy koszt działania i większa wydajność na token, co docenia branża. Równocześnie pojawiają się opinie, że realna efektywność modeli w praktycznych zadaniach kodowania może się różnić od wyników benchmarkowych.
artificialanalysis.ai · reddit.com · officechai.com
Gemini 3.1 Pro Preview – naprawa problemów z halucynacjami i raporty z testów
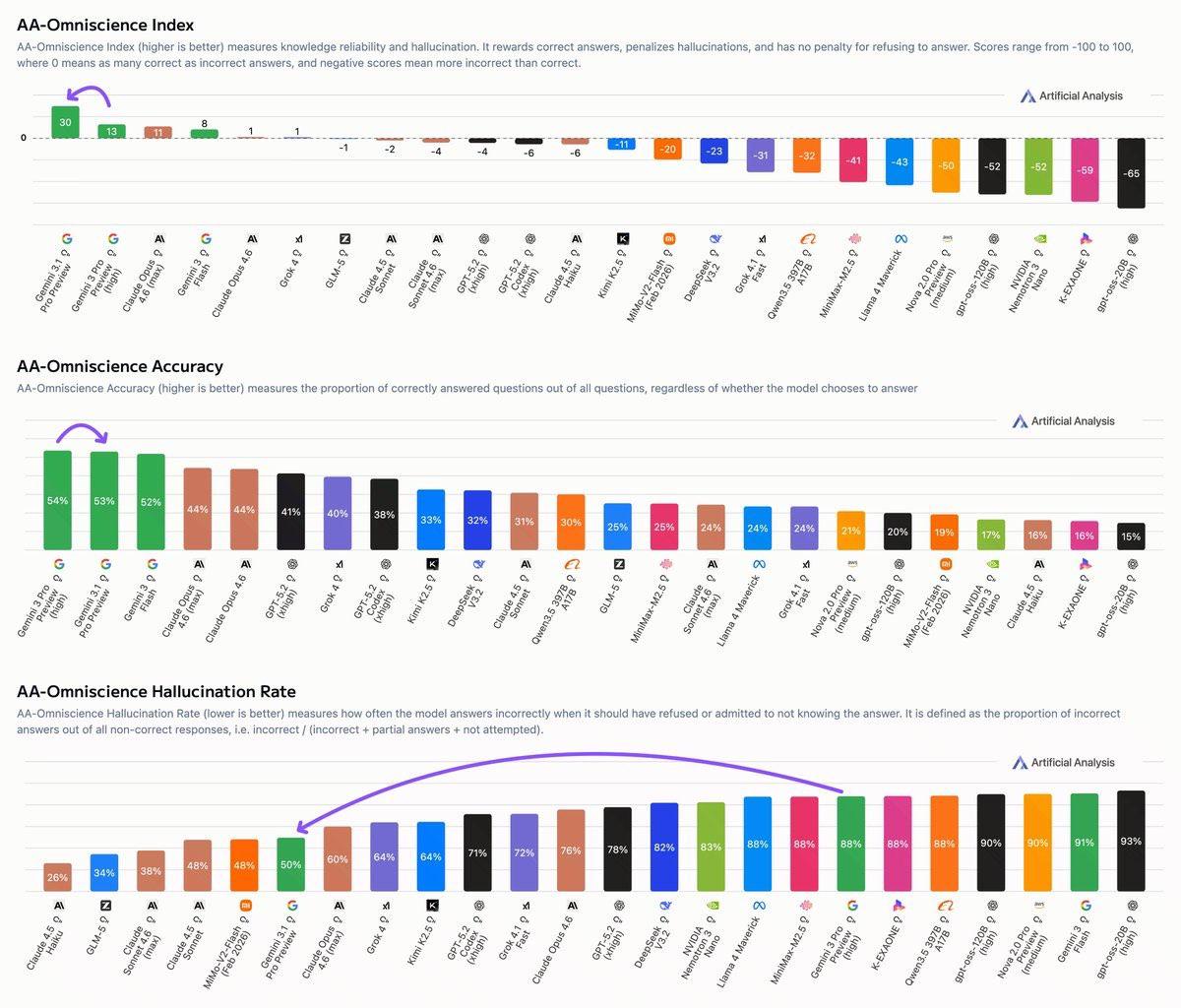
Google wprowadziło Gemini 3.1 Pro Preview jako model z zaawansowanym rozumowaniem i dużo wyższą poprawnością odpowiedzi niż poprzednie wersje. W testach (ARC-AGI-2 – 77,1%) wypada znakomicie, a oficjalnie podkreślono też postęp w ograniczaniu tzw. halucynacji (fałszywych odpowiedzi). Rzeczywiste testy wskazują jednak, że choć model radzi sobie świetnie z wieloetapowymi problemami matematycznymi i jest bardziej spójny, to nadal w nietypowych bądź nowatorskich pytaniach może generować błędne rozwiązania – niemniej znacznie rzadziej niż wcześniej.
blog.google · ai.google.dev · theneuron.ai
Humorystyczne porównanie Gemini 3 Pro i Gemini 3.1 Pro – większa moc i lepsze funkcje nowego modelu
Obrazek w humorystyczny sposób porównuje dwa modele Gemini: „3 Pro” i nowe „3.1 Pro”. Nowa wersja, przedstawiona jako silny osiłek, jest znacznie potężniejsza – co odzwierciedla faktyczne dane z benchmarków, potwierdzając że różnica nie ogranicza się do żartu graficznego. Motyw przewodni – Gemini jako „większy, silniejszy i bardziej zaawansowany” – odzwierciedla skok technologiczny nowego modelu.
Gemini 3.1 Pro i test myjni – model popisuje się zdrowym rozsądkiem
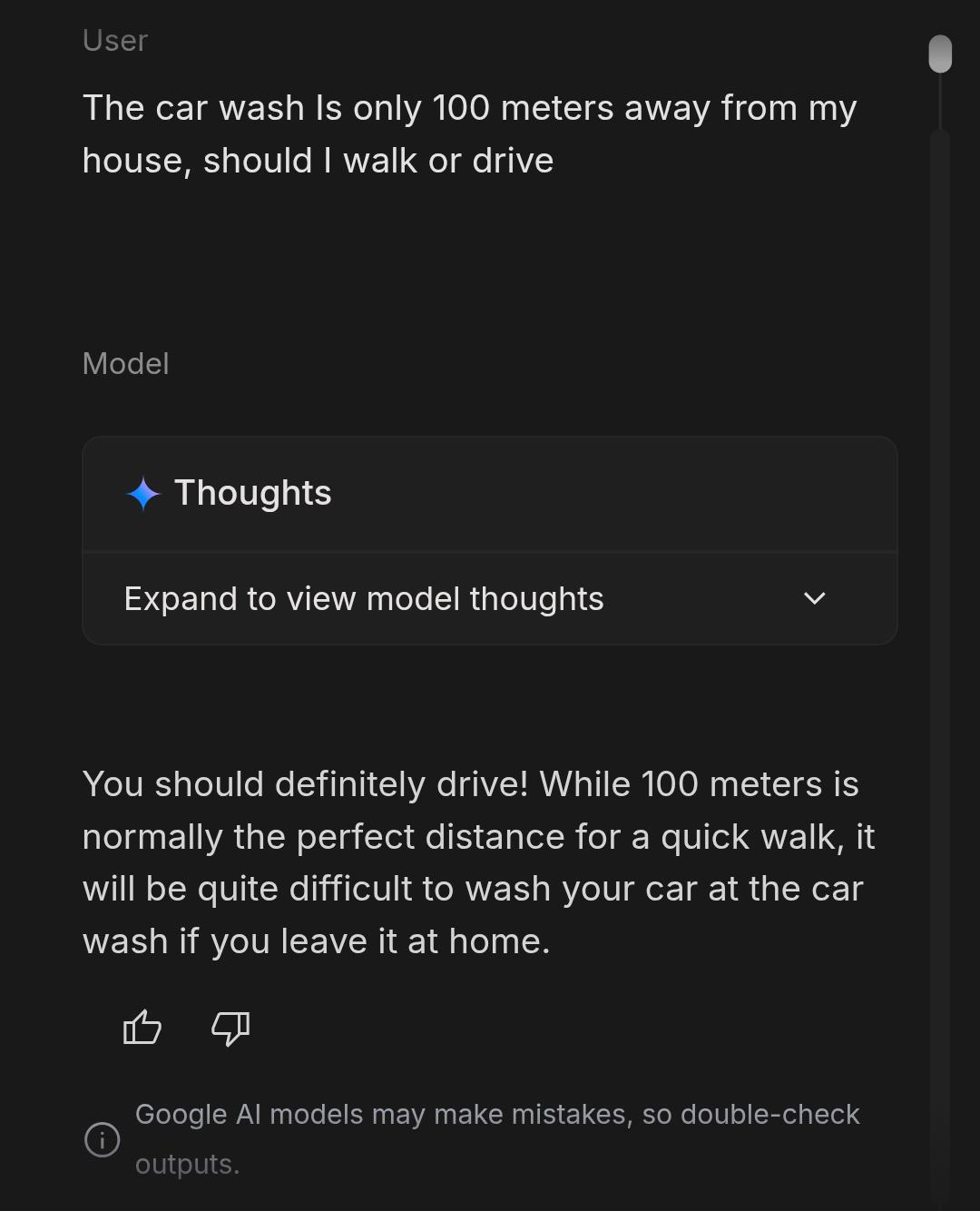
Nowy Gemini 3.1 Pro dokonał pozytywnej rewolucji w słynnym „car wash test” – typowym pytaniu sprawdzającym umiejętność rozumowania. Gdy użytkownik zapytał, czy idąc pieszo czy jadąc autem do pobliskiej myjni lepiej umyć auto, model poprawnie zasugerował skorzystanie z samochodu, bo auto musi być fizycznie na miejscu. Większość innych modeli AI (w tym ChatGPT, Claude) mylnie wybierała chodzenie, kierując się wygodą lub ekologią, nie zauważając sedna problemu.
medium.com · cybernews.com · zdnet.com
Google poprawia wyniki modeli AI o 19% dzięki prostym zmianom w aktualizacji parametrów
Nowatorskie podejście Google polegające na losowym pomijaniu 50% aktualizacji parametrów przy uczeniu modelu (tzw. „maskowanie” gradientów) pozwoliło zwiększyć wydajność modeli aż o 19% przy braku dodatkowego zużycia zasobów. Metoda jest prosta do wdrożenia i może radykalnie zredukować koszty oraz przyspieszyć rozwój nowych systemów AI na całym świecie.
arxiv.org